Architettura CPU e fattori che determinano le prestazioni: multicore, edb, gpu integrata, overclocking e throttling, frequenza di FSB, frequenza di clock...
L'architettura della CPU (Central Processing Unit) gioca un ruolo centrale nel cuore dei sistemi informatici, determinando come le istruzioni vengono eseguite e come i dati vengono processati. Due paradigmi principali che hanno influenzato l'evoluzione delle architetture CPU sono RISC (Reduced Instruction Set Computing) e CISC (Complex Instruction Set Computing). In questo articolo, esploreremo le caratteristiche chiave di entrambe le architetture, evidenziando le differenze fondamentali e le implicazioni pratiche.
Architettura RISC (Reduced Instruction Set Computing)
RISC abbraccia la filosofia della semplicità e dell'efficienza. In questo approccio, il set di istruzioni è ridotto al minimo essenziale, e ogni istruzione esegue operazioni di base. Questa architettura favorisce l'esecuzione di istruzioni in tempi più brevi, permettendo un ciclo di clock più veloce. I processori RISC spesso caricano e archiviano dati dalla memoria più velocemente, contribuendo a prestazioni elevate.
- Istruzioni Semplici: Le CPU RISC utilizzano un set di istruzioni più ridotto e fondamentalmente più semplice. Ogni istruzione svolge un compito di base, e il numero di istruzioni nel set è limitato.
- Esecuzione Veloce: Poiché le istruzioni sono più elementari, la loro esecuzione richiede meno cicli di clock. Le CPU RISC tendono ad essere più veloci nell'esecuzione di istruzioni semplici.
- Pipeline Profondo: Molte CPU RISC utilizzano una pipeline più profonda, consentendo l'esecuzione simultanea di diverse fasi di un'istruzione.
- Caratteristiche: Sono spesso dotate di registri generali più numerosi e operazioni aritmetiche efficienti. Tuttavia, alcune operazioni più complesse possono richiedere più istruzioni.
Architettura CISC (Complex Instruction Set Computing)
CISC, d'altro canto, si caratterizza per un set di istruzioni più ampio e complesso. Le istruzioni CISC spesso eseguono operazioni più complesse in una singola istruzione, riducendo il numero complessivo di istruzioni necessarie per completare una determinata attività. Questa architettura mira a massimizzare l'efficienza dell'hardware e può ridurre il carico di lavoro del programmatore.
- Istruzioni Complesse: Le CPU CISC hanno un set di istruzioni più ampio e complesso. Una singola istruzione CISC può eseguire compiti più avanzati rispetto alle istruzioni RISC.
- Esecuzione più Lenta: Le istruzioni più complesse richiedono generalmente più cicli di clock per l'esecuzione, rendendo le CPU CISC potenzialmente più lente nell'esecuzione di singole istruzioni.
- Numero di Registri: Le CPU CISC possono avere un numero di registri generali inferiore rispetto alle CPU RISC, ma le istruzioni più complesse possono implicare meno istruzioni complessive per compiere una data operazione.
- Caratteristiche: Le istruzioni CISC possono comprendere operazioni di memoria, operazioni aritmetiche complesse e altre funzionalità avanzate all'interno di una singola istruzione.
Entrambe le architetture hanno vantaggi e svantaggi, e la scelta tra RISC e CISC dipende dall'applicazione e dai requisiti specifici del sistema. Mentre le CPU RISC sono spesso preferite per applicazioni in cui la velocità di esecuzione è critica, le CPU CISC possono essere più adatte per compiti che richiedono istruzioni complesse e avanzate.
Incremento di prestazioni della CPU
Nel dinamico mondo dell'informatica, dove il tempo è spesso misurato in cicli di clock e nanosecondi, la costante ricerca di miglioramenti nelle prestazioni delle CPU è un'impresa avvincente. L'aumento delle prestazioni non è solo un obiettivo, ma una necessità imperativa in un'era in cui le applicazioni richiedono sempre più potenza computazionale.
L'incremento delle prestazioni di una CPU può essere ottenuto attraverso diverse strategie e ottimizzazioni.
Aumento della Velocità di Clock
Nel costante balletto tra potenza di calcolo e velocità di esecuzione, l'aumento della velocità di clock emerge come uno dei protagonisti principali. Nelle CPU (Central Processing Unit), il clock, misurato in cicli al secondo, è il metronomo che guida l'orchestra di istruzioni, definendo la velocità di esecuzione.
L'aumento della velocità di clock, anche noto come overclocking, è una pratica che consiste nel aumentare la frequenza di clock di un processore al di sopra delle specifiche di fabbrica o delle impostazioni predefinite. La frequenza di clock è misurata in cicli al secondo (Hertz) e rappresenta la velocità a cui un processore esegue le sue operazioni.
Quando si aumenta la velocità di clock di una CPU, si aumenta la frequenza di funzionamento, consentendo al processore di eseguire più istruzioni in un determinato periodo di tempo. Questa pratica può portare a un aumento delle prestazioni del processore e, di conseguenza, a una maggiore velocità di esecuzione delle operazioni.
Tuttavia, ci sono alcune considerazioni importanti legate all'aumento della velocità di clock:
- Rischi di Instabilità: Aumentare la frequenza di clock oltre i limiti consigliati può rendere il sistema instabile, con possibili crash del sistema o errori di elaborazione.
- Rischi di Riscaldamento: L'aumento della frequenza di clock genera più calore. Se il sistema di raffreddamento non è in grado di dissipare il calore in eccesso, potrebbero verificarsi problemi di surriscaldamento, compromettendo le prestazioni e la durata della CPU.
- Garanzia e Sicurezza: L'overclocking può annullare la garanzia del produttore e potrebbe causare danni permanenti alla CPU se non fatto correttamente.
- Compatibilità con Componenti: Aumentare la frequenza di clock può influire sulla stabilità di altri componenti del sistema, come la memoria RAM o la scheda madre. È importante assicurarsi che tutti i componenti siano compatibili con le nuove impostazioni.
L'aumento della velocità di clock è spesso praticato da appassionati di hardware o utenti avanzati che desiderano ottenere prestazioni aggiuntive dal loro hardware. Tuttavia, è fondamentale procedere con attenzione, utilizzando strumenti appropriati e monitorando attentamente le temperature e la stabilità del sistema durante l'overclocking.
Parallelismo
Nel vasto oceano dell'innovazione informatica, la ricerca incessante di aumentare le prestazioni delle CPU si è incanalata in una direzione avvincente: il parallelismo. Immaginate una strada in cui non avanzate solo in una corsia, ma in una superstrada con corsie multiple, accelerando il vostro viaggio. Questa è l'essenza del parallelismo, un concetto che sta trasformando la maniera in cui le nostre CPU affrontano compiti complessi e affamati di risorse.
Il parallelismo ha tre Anime: Istruzioni, Thread e Dati
Il parallelismo a livello di istruzione (ILP) permette alle CPU di eseguire più comandi in parallelo, accelerando il flusso delle istruzioni. Nel mondo del thread, il parallelismo a livello di thread (TLP) consente l'esecuzione simultanea di diverse sequenze di istruzioni, portando la multitasking a nuovi livelli. Infine, il parallelismo a livello di dati (DLP) scolpisce la strada per operazioni concorrenti su set di dati separati, aprendo un mondo di opportunità per applicazioni intensive di dati.
Cache più veloci e più grandi
L'ottimizzazione delle prestazioni della CPU attraverso la progettazione di cache più veloci e più grandi è una pratica chiave nell'evoluzione delle architetture dei processori. La cache è una memoria di livello più vicino alla CPU rispetto alla memoria principale (RAM), ed è utilizzata per archiviare dati e istruzioni frequentemente utilizzati. Un'efficiente progettazione della cache può contribuire in modo significativo al miglioramento delle prestazioni complessive del sistema.
Cache più grandi: Un'espansione della capacità della cache consente di immagazzinare più dati e istruzioni in essa. Questo può ridurre la necessità di accedere alla memoria principale, aumentando così l'efficienza complessiva del sistema e sfruttando meglio la larghezza di banda della cache. Si aumenta la probabilità che i dati richiesti siano già presenti in cache (hit). Ciò riduce la frequenza di accessi alla memoria principale, migliorando le prestazioni complessive.
Cache più veloci: Avere una cache con tempi di accesso più brevi consente alla CPU di recuperare i dati in modo più rapido. Ciò è particolarmente cruciale poiché la cache viene utilizzata per archiviare dati a cui la CPU accede frequentemente durante le operazioni. I processori moderni spesso eseguono più istruzioni contemporaneamente, richiedendo un accesso rapido a dati indipendenti. Cache più veloci facilitano la gestione di accessi simultanei.
In conclusione, cache più veloci e più grandi rappresentano una strategia chiave per ottimizzare le prestazioni della CPU. Tuttavia, è un compromesso delicato tra dimensioni, velocità e complessità del design, che richiede una progettazione attenta per garantire il massimo beneficio nelle diverse applicazioni e scenari d'uso.
Architettura Pipelined e Superpipelined
L'architettura pipelined e superpipelined sono due approcci progettuali che mirano a migliorare l'efficienza nell'esecuzione di istruzioni in una CPU. Entrambi fanno parte della famiglia delle architetture pipeline, che cercano di scomporre il processo di esecuzione di un'istruzione in più fasi sequenziali.
L'architettura pipelined suddivide il percorso di esecuzione delle istruzioni in diverse fasi, consentendo l'esecuzione simultanea di più istruzioni. Le fasi includono recuperare l'istruzione dalla memoria, decodificarla, eseguire l'operazione, accedere alla memoria e scrivere i risultati. Ogni fase è gestita da un'unità di elaborazione specializzata. Mentre un'istruzione avanza da una fase all'altra, la CPU può iniziare ad eseguire la successiva. Questo aumenta l'efficienza complessiva della CPU.
L'architettura superpipelined va oltre, suddividendo ulteriormente le fasi della pipeline rispetto a un'architettura pipelined tradizionale.
Entrambe mirano a migliorare l'efficienza attraverso la parallelizzazione delle operazioni ma l'architettura superpipelined cerca di ottenere velocità di clock più elevate attraverso pipeline più corte, ma introduce sfide aggiuntive nella gestione della complessità del design.
In conclusione, sia l'architettura pipelined che quella superpipelined rappresentano approcci avanzati nell'ottimizzazione delle prestazioni delle CPU attraverso la parallelizzazione delle operazioni. La scelta tra i due dipenderà dalle specifiche esigenze di prestazioni e complessità di progettazione del sistema.
Processori multicore
Il multicore è una risposta ingegnosa alla crescente domanda di potenza di calcolo. Invece di affidare tutto il carico di lavoro a un singolo cuore, le CPU multicore adottano un approccio sinfonico, con due o più core che lavorano in armonia per gestire una miriade di compiti. Questa distribuzione del carico di lavoro porta a prestazioni migliori, consentendo al sistema di eseguire più attività contemporaneamente.
I processori multi-core sono chip che contengono più di un nucleo di elaborazione all'interno di un singolo processore fisico. Questi nuclei operano indipendentemente gli uni dagli altri, consentendo al processore di gestire più attività contemporaneamente.
Che cos'è un core?
Un "core" rappresenta un'unità di elaborazione indipendente all'interno di un processore. I processori multi-core contengono due o più di questi nuclei. Un processore può contenere uno o più di questi core, ciascuno dei quali funziona come una CPU separata e completa. I core all'interno di un processore sono progettati per eseguire istruzioni in modo indipendente, consentendo l'esecuzione simultanea di più attività.
Il numero di core è diventato un importante indicatore delle capacità di prestazioni di una CPU, ma è importante notare che la quantità di core da sola non determina completamente le prestazioni. Fattori come la frequenza di clock, l'architettura del core, la cache e altri elementi influenzano anche le prestazioni complessive del processore. La scelta del numero di core dipende dalle esigenze specifiche dell'utente e dal tipo di applicazioni che verranno eseguite sulla CPU.
| Processore | Numero di Core | Freq. di Clock | Cache L3 | Tecnologia di Processo | Architettura | Uso Principale |
|---|---|---|---|---|---|---|
| Intel Core i5-11600K | 6 | 3.9 GHz | 12 MB | 10nm SuperFin | Willow Cove | Gaming, Uso Generale |
| AMD Ryzen 7 5800X | 8 | 3.8 GHz | 32 MB | 7nm Zen 3 | Zen 3 | Gaming, Produttività |
| Intel Core i9-11900K | 8 | 3.5 GHz | 16 MB | 10nm SuperFin | Cypress Cove | Gaming, Prestazioni Elevate |
| AMD Ryzen 9 5950X | 16 | 3.4 GHz | 64 MB | 7nm Zen 3 | Zen 3 | Elaborazioni Multitasking, Produttività |
| Apple M1 (chip ARM) | 8 | - | 12 MB | 5nm | Apple Silicon | MacBook, iPad Pro |
| Qualcomm Snapdragon 888 | 8 | - | - | 5nm | Kryo 680 | Smartphone di Fascia Alta |
| NVIDIA A100 Tensor Core GPU | 54 | - | 40 MB | 7nm | Ampere GPU | Elaborazione di Carichi di Lavoro di IA |
I processori multi-core sono diventati comuni nelle configurazioni di computer moderni, migliorando la capacità di gestire carichi di lavoro complessi e migliorando le prestazioni complessive del sistema.
Soluzioni trovate da Intel e AMD
Intel e AMD, due dei principali produttori di processori al mondo, utilizzano approcci simili per migliorare le prestazioni delle loro CPU, ma hanno anche differenze nelle rispettive architetture e strategie di progettazione. Ecco un'occhiata a come entrambe le aziende lavorano per aumentare le prestazioni dei loro processori:
Intel:
- Architettura Core: Intel utilizza l'architettura Core per i suoi processori, che include caratteristiche come l'Hyper-Threading (per l'esecuzione simultanea di più thread) e una pipeline più lunga per il superpipelining.
- Tecnologie Specifiche: Intel ha sviluppato e implementato diverse tecnologie specifiche per migliorare le prestazioni, come Turbo Boost (aumento dinamico della frequenza di clock in base al carico di lavoro) e Advanced Vector Extensions (AVX) per accelerare operazioni di calcolo intensivo.
- Processo di Produzione: Intel è stata all'avanguardia nella miniaturizzazione dei transistor attraverso il processo di produzione, passando a nodi tecnologici più avanzati per migliorare l'efficienza energetica e la densità di transistor.
AMD:
- Architettura Zen: AMD ha introdotto l'architettura Zen per i suoi processori Ryzen, caratterizzata da core multipli e un approccio modulare. Zen 3, l'ultima iterazione, ha portato miglioramenti significativi nelle prestazioni per ciclo di clock.
- Infinity Fabric: AMD utilizza Infinity Fabric, una tecnologia di connettività ad alta larghezza di banda, per collegare i diversi componenti all'interno della CPU, inclusi i core della CPU e i controller di memoria.
- Simultaneous Multithreading (SMT): Analogamente all'Hyper-Threading di Intel, SMT di AMD consente l'esecuzione simultanea di più thread su ogni core, migliorando l'utilizzo delle risorse.
- Processo di Produzione: AMD ha adottato anche nodi tecnologici avanzati per la produzione dei suoi processori, cercando di mantenere un passo competitivo con Intel in termini di efficienza e prestazioni.
Entrambe le aziende investono notevolmente nella ricerca e sviluppo per migliorare le loro architetture, introdurre nuove tecnologie e avanzare nei processi di produzione, il che si traduce in costanti progressi nelle prestazioni delle loro CPU.
Frequenza di clock
La potenza di una CPU è misurata in base alla velocità e alla quantità di dati che è in grado di elaborare.
La frequenza di clock di una CPU rappresenta il numero di cicli di clock che la CPU può eseguire in un secondo. Questa misura è espressa in Hertz (Hz) e spesso misurata in gigahertz (GHz) o megahertz (MHz) nelle CPU moderne.
Ogni ciclo di clock rappresenta un'unità di tempo durante la quale la CPU può eseguire operazioni. Quindi, una CPU con una frequenza di clock più elevata può eseguire un numero maggiore di operazioni in un dato periodo di tempo rispetto a una CPU con una frequenza di clock inferiore.
È importante notare che la frequenza di clock da sola potrebbe non essere l'unico indicatore delle prestazioni di una CPU. Altri fattori come l'architettura della CPU, il numero di core, la presenza di tecnologie di ottimizzazione delle prestazioni e altri elementi contribuiscono alla determinazione delle reali capacità di elaborazione della CPU.
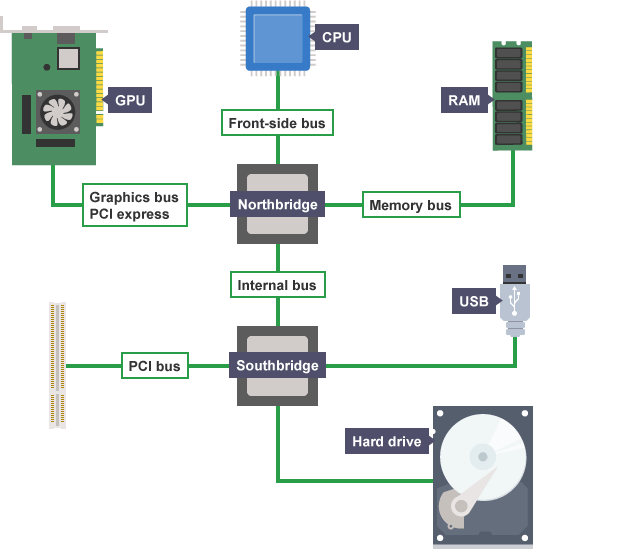
La frequenza di FSB
La Frequenza di Bus di Sistema (FSB, dall'inglese Front Side Bus) è un elemento importante nel determinare la frequenza di clock di una CPU. La FSB è il canale attraverso il quale la CPU comunica con il chipset sulla scheda madre. La frequenza di clock della FSB influisce direttamente sulla velocità di trasmissione dei dati tra la CPU e altri componenti del sistema, come la memoria RAM.
In passato, la FSB era un parametro cruciale per definire la velocità complessiva di una CPU. Tuttavia, con l'avanzare della tecnologia, soprattutto con l'introduzione dell'architettura multicore e delle memorie cache integrate direttamente sulla CPU, il ruolo della FSB è cambiato. In molte architetture moderne, come quelle di Intel e AMD, la comunicazione tra i componenti interni della CPU avviene a velocità molto elevate senza dover passare attraverso la FSB tradizionale.
Quindi, mentre la FSB può ancora essere un fattore rilevante in alcuni sistemi più datati o specifici, nelle moderne architetture la frequenza di clock della CPU e la gestione interna della cache sono aspetti più determinanti delle prestazioni globali.
Overclocking e Throttling
Il "throttling" e l'"overclocking" sono due concetti opposti legati alle prestazioni di una CPU.
- Throttling:
- Definizione: Il throttling è una tecnica utilizzata per ridurre dinamicamente la velocità di clock di una CPU o di altri componenti del sistema per mantenere la temperatura o il consumo energetico entro determinati limiti.
- Scopo: Il throttling è progettato per evitare il surriscaldamento eccessivo del processore, il che potrebbe danneggiarlo. Quando la CPU raggiunge temperature critiche o il sistema rileva un consumo energetico troppo elevato, può ridurre temporaneamente la sua velocità di clock per dissipare il calore in eccesso.
- Overclocking:
- Definizione: L'overclocking è il processo intenzionale di aumentare la velocità di clock di una CPU oltre le specifiche del produttore per ottenere prestazioni superiori.
- Scopo: Gli appassionati di hardware spesso praticano l'overclocking per ottenere prestazioni extra dalla CPU. Tuttavia, l'overclocking aumenta il calore generato dalla CPU, e di conseguenza, può richiedere soluzioni di raffreddamento più avanzate.
Entrambi i concetti possono avere impatti significativi sulle prestazioni di un sistema e devono essere gestiti attentamente per evitare danni ai componenti hardware. Throttling e overclocking sono spesso regolati tramite le impostazioni del BIOS o dell'UEFI della scheda madre.
GPU integrata
Le GPU integrate sulla CPU, spesso chiamate GPU integrate o grafica integrata, sono componenti grafiche incorporate direttamente nel processore (CPU). Questa integrazione consente di gestire le operazioni grafiche senza la necessità di una scheda grafica discreta separata. Ecco alcune informazioni chiave su GPU integrate:
- Scopo Principale:
- Le GPU integrate sono progettate principalmente per fornire funzionalità grafiche di base per il normale utilizzo del computer. Sono adatte per attività quotidiane come la navigazione web, l'uso di applicazioni di produttività e la riproduzione di contenuti multimediali.
- Economia Energetica:
- Le GPU integrate sono spesso progettate con un'enfasi sulla bassa potenza e l'efficienza energetica. Ciò le rende adatte per sistemi portatili, ultrabook e dispositivi con limitazioni di potenza.
- Condivisione di Risorse:
- Poiché la GPU integrata condivide la memoria di sistema con la CPU, non ha la sua memoria video dedicata. Questo significa che la quantità di memoria disponibile per la grafica è limitata rispetto alle soluzioni con schede grafiche discrete.
- Prestazioni Limitate:
- Le GPU integrate solitamente offrono prestazioni grafiche limitate rispetto alle schede grafiche discrete. Sono idonee per l'utilizzo generale, ma potrebbero non essere sufficienti per applicazioni grafiche intensive o per il gioco avanzato.
- Evoluzione e Miglioramenti:
- Nel corso degli anni, le GPU integrate sono migliorate in modo significativo in termini di prestazioni. Alcuni modelli supportano anche funzionalità avanzate come la decodifica hardware dei video e le prestazioni di base per il gaming leggero.
- Supporto per Monitor Multipli:
- Molte GPU integrate supportano la connessione a più monitor contemporaneamente. Ciò è utile per utenti che richiedono uno spazio desktop esteso o che lavorano con applicazioni che beneficiano di più schermi.
- Integrazione con CPU:
- Le GPU integrate sono parte integrante della CPU e condividono la stessa interfaccia elettronica. Questo consente una comunicazione più efficiente tra CPU e GPU, migliorando l'efficienza complessiva del sistema.
- Adatte per Uso Generale:
- Le GPU integrate sono adatte per utenti che non richiedono prestazioni grafiche elevate, come gli utenti orientati alla produttività e alla navigazione web. Tuttavia, per applicazioni più esigenti, come il rendering 3D avanzato o il gaming di fascia alta, potrebbe essere necessaria una scheda grafica discreta.
In sintesi, le GPU integrate offrono una soluzione grafica conveniente e efficiente per l'uso quotidiano su una vasta gamma di dispositivi, garantendo al contempo una maggiore autonomia della batteria e una minore produzione di calore rispetto alle schede grafiche discrete.
EDB
L'Execute Disable Bit (EDB) è una tecnologia di sicurezza hardware implementata nei processori per prevenire attacchi di tipo buffer overflow. Essenzialmente, EDB impedisce l'esecuzione di codice dannoso che potrebbe sfruttare vulnerabilità nei programmi, contribuendo a proteggere il sistema da minacce informatiche.
Sintesi delle caratteristiche principali:
- Prevenzione Buffer Overflow: EDB protegge contro vulnerabilità che consentono agli attaccanti di sovrascrivere la memoria oltre i limiti del buffer.
- Funzionamento Hardware: L'implementazione avviene a livello hardware, impedendo l'esecuzione di istruzioni in aree di memoria designate per i dati.
- Bit di Esecuzione: L'uso di un "bit di esecuzione" associato a ciascuna pagina di memoria determina se il codice in quella pagina può essere eseguito o meno.
- Compatibilità Software: Richiede il supporto sia a livello hardware che software, con sistemi operativi moderni progettati per collaborare con EDB.
- Abilitazione nel BIOS: Può essere attivato o disattivato tramite le impostazioni del BIOS o dell'UEFI e dipende dalla compatibilità del processore e del chipset.
Perché migliora la CPU:
- Protezione da Attacchi: EDB migliora la sicurezza del sistema proteggendolo da attacchi informatici che sfruttano vulnerabilità software comuni, come i buffer overflow.
- Prevenzione di Codice Dannoso: Impedendo l'esecuzione di codice dannoso, EDB riduce il rischio di infezioni da malware e attività dannose.
- Sicurezza a Livello Hardware: Essendo implementato a livello hardware, EDB fornisce un livello aggiuntivo di protezione indipendentemente dalle misure software.
In sintesi, l'Execute Disable Bit è una caratteristica che migliora la sicurezza dei processori, contribuendo a rendere i sistemi più resilienti contro minacce informatiche comuni.
INDICE
Avviare il computer
- Bios UEFI
- POST, BIOS e UEFI
- BIOS e CMOS
- Configurazione file UEFI
- Sicurezza di BIOS e UEFI
- Aggiornamento del Firmware
Alimentazione del computer
Funzionalità avanzate
- Architettura CPU RISC e CISC e prestazioni
- Metodi di raffreddamento CPU
- Che cos'è il RAID
- Porte obsolete
- Connettori USB
- Connettori e cavi SATA
- Il monitor
Configurazione del computer
- Aggiornamento hardware del computer
- Configurazione workstation CAx
- Configurazione workstation per montaggio audio e video
- Configurazione workstation per la virtualizzazione
- Configurazione di computer da gioco
- Thick client e thin client
- Dispositivi NAS











